Harness Engineering: Environment Design Guide for AI Agent Production
If you've ever deployed an AI agent to production, you've probably experienced this at least once: the model is smart enough, but the results are just not trustworthy. No matter how much you refine the prompt, the fundamental instability never goes away. By the end of this article, you'll understand the real cause of that instability and be able to design an agent harness yourself and apply it directly to your team's codebase. This piece covers the Harness Engineering paradigm — rapidly taking shape as OpenAI, Anthropic, and Thoughtworks published official articles in quick succession in early 2026 — with practical examples aimed at both teams introducing AI agents for the first time and teams looking to stabilize agents already in production.
Core Concepts
"It's Not the Horse — It's the Harness"
Harness is a metaphor from the equipment used to control a horse. Expressed as a formula:
AI Model (horse) + Harness (environment & control) = AgentThe bottom line is this: an agent's real competitive edge comes not from the model itself, but from the system designed around it. Whether it's Claude, GPT-4, or Gemini, the major models of 2026 are converging to a similar level. That means swapping out the model doesn't dramatically change performance. The harness is what makes the real difference.
This perspective isn't a complete break from traditional MLOps or DevOps. Just as MLOps engineers model training and deployment pipelines, harness engineering engineers the entire execution environment in which an already-deployed inference model operates. The difference is that the subject is not a pipeline but the agent's context and authority.
What a Harness Includes
- The list of tools the agent can call
- The source and form of information (context) the agent accesses
- The agent's decision validation method
- The criteria for when the agent should stop
- The overall development environment: repository structure, CI configuration, linter, formatter, etc.
The Evolution: Prompt → Context → Harness
Prompt Engineering → Designing what to say to the model
Context Engineering → Designing what information the model can see
Harness Engineering → Designing the entire environment in which the model operatesWhat is a Context Window? It is the maximum range of text an LLM can process at once. Information that doesn't fit within this window cannot be referenced by the agent. Team knowledge buried in Slack threads or Google Docs falls exactly into this category.
As the OpenAI team put it, you need to give the agent a map, not a 1,000-page manual. Knowledge that lives outside the codebase simply doesn't exist for the agent.
The 3 Components of a Harness (Birgitta Böckeler's Classification)
This is the classification compiled by Thoughtworks Distinguished Engineer Birgitta Böckeler on martinfowler.com. It is often cited as "the Martin Fowler classification," but Böckeler is the actual author.
| Component | Description |
|---|---|
| Context Engineering | Knowledge base embedded in the codebase + dynamic sources such as observability data and browser navigation |
| Architectural Constraints | LLM-based guardrails + deterministic structural tests |
| Garbage Collection | Automated/manual detection and removal of dead code, unnecessary files, and convention drift |
ArchUnit, which appears under Architectural Constraints, is a testing tool that automatically validates code dependency rules. It is used to enforce architectural rules in CI that an LLM might violate — for example, "the service layer must not directly reference the controller."
Practical Application
Designing a Harness with the IMPACT Framework
This is a checklist you can use when designing an agent harness from scratch. You can see how each item is implemented in the code examples that follow.
| Element | Description | Practical Question |
|---|---|---|
| Intent | Define the agent's purpose and goals | What should this agent do? |
| Memory | Manage short-term and long-term memory | What needs to be remembered across sessions? |
| Planning | Break down tasks and build a plan | How do we decompose a large task? |
| Authority | Restrict the scope of agent permissions | What should the agent never touch? |
| Control Flow | Manage execution flow and error handling | How do we recover on failure? |
| Tools | Define available tools | What is the minimum set of tools required? |
Example 1: Short-Term Task — 2-Agent Research & Writing Pipeline
This is the most fundamental harness pattern, separating Research from Writing. shared_state acts as shared memory between agents. In the code below, research_agent writes its results to shared_state, and writing_agent reads directly from it.
import anthropic
client = anthropic.Anthropic()
# Shared state: data-passing hub between agents (Memory)
shared_state: dict = {
"topic": "",
"research_result": "",
}
def research_agent(topic: str) -> str:
"""Intent: Research the topic and store a structured summary in shared state"""
try:
response = client.messages.create(
model="claude-opus-4-6",
max_tokens=2048,
system="""You are a technical research specialist.
Research the given topic and summarize the key findings in bullet points.
Output the results in a structured format that the next agent can use.""",
messages=[{"role": "user", "content": f"Research the following topic: {topic}"}]
)
result = response.content[0].text
shared_state["research_result"] = result # Memory: save to shared state
return result
except anthropic.APIError as e:
print(f"[research_agent] API error: {e}")
raise
def writing_agent(tone: str = "technical blog") -> str:
"""Intent: Read research results from shared state and draft a blog post"""
research = shared_state.get("research_result", "")
if not research:
raise ValueError("No research results found. Run research_agent first.")
try:
response = client.messages.create(
model="claude-opus-4-6",
max_tokens=4096,
system=f"""You are a professional {tone} writer.
Write a reader-friendly blog post based on the provided research material.
Use markdown format and include code examples.""",
messages=[{
"role": "user",
"content": f"Write a blog post using the following research material:\n\n{research}"
}]
)
return response.content[0].text
except anthropic.APIError as e:
print(f"[writing_agent] API error: {e}")
raise
def run_blog_harness(topic: str) -> str:
shared_state["topic"] = topic
research_agent(topic) # → updates shared_state["research_result"]
blog_post = writing_agent() # ← reads shared_state["research_result"]
return blog_post
result = run_blog_harness("Harness Engineering")Analyzing this harness from the IMPACT perspective:
| Element | Implementation |
|---|---|
| Intent | Each agent performs only one role (role separation) |
| Memory | shared_state["research_result"] serves as shared memory between agents |
| Authority | Each agent can only call the Claude API; no filesystem access |
| Control Flow | If research_agent fails, writing_agent cannot proceed (enforced ordering) |
| Tools | Single tool per agent (Claude API), adhering to the principle of least privilege |
Example 2: Long-Running Task — Anthropic 3-Agent Harness
Used for tasks that exceed a single agent's context window, such as multi-hour coding tasks. The core mechanism is context isolation: each agent has an independent context window, and only summarized outputs are passed between stages. This means that even if one agent's context fills up, the entire pipeline does not halt.
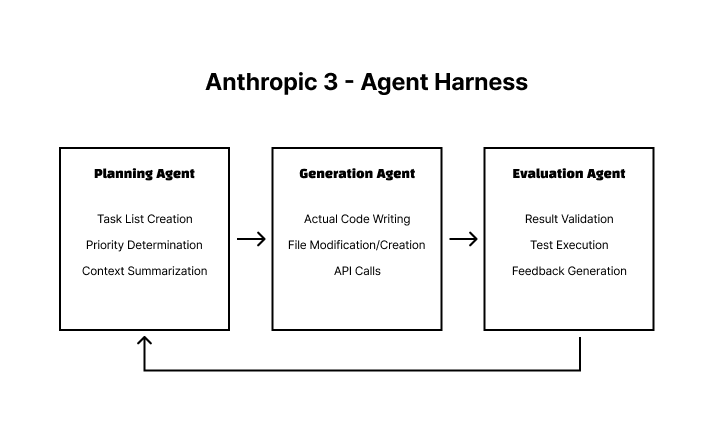
Viewed through the IMPACT lens, each stage maps as follows:
- Planning: Handles task decomposition (P) and intent (I) definition
- Generation: Handles tool (T) use and control flow (C)
- Evaluation: Handles authority boundary (A) validation and the feedback loop (C)
Example 3: Team Environment — Configuring the Claude Code Harness with CLAUDE.md
If you use Claude Code as a team agent, CLAUDE.md is effectively your harness configuration file. The 6 IMPACT elements can be mapped directly as sections.
# CLAUDE.md (example harness configuration)
## Agent Purpose (Intent)
- Maintain and add features to the backend API of this repository.
- Frontend changes are out of scope.
## Permitted Tool Scope (Authority)
- File read/write: src/ directory only
- Never modify: .env, secrets/, prisma/migrations/
- Always request human review before changing the DB schema
## Context Guide (Context Engineering)
- Architecture decisions: refer to /docs/adr/
- API specification: refer to /docs/openapi.yaml
- Coding conventions: refer to /docs/conventions.md
## Execution Flow Rules (Control Flow)
- Stop immediately if a potential external API key exposure is detected
- Do not modify business logic without testsPros and Cons
Advantages: Why Harness Engineering Now
| Item | Detail |
|---|---|
| Predictability | Agent behavior is controlled through environment design, making results stable |
| Scalability | Performance can be improved by refining the harness alone, without swapping models |
| Productivity | 10× speed improvement over manual work, per OpenAI experiments |
| Model Independence | Competitive advantage secured at the system level, not tied to a specific LLM |
| Long-Session Support | 3-agent separation structurally overcomes context window limits |
Disadvantages and Caveats
| Item | Detail | Mitigation |
|---|---|---|
| Design Complexity | The harness itself increases engineering complexity | Start with 2 agents and expand as needed |
| Garbage Accumulation | Dead code and unnecessary files generated by agents | Regular garbage collection routines are essential |
| Context Design Overhead | Information the agent accesses must be structured | Start by organizing CLAUDE.md, ADRs, and OpenAPI specs |
| Excessive Control Flow | Complex conditional branching can confuse agents | Follow the atomic tool design principle |
| Learning Curve | Requires a different mindset from traditional prompt engineering | Use the IMPACT framework for a structured approach |
Atomic tool design is the principle of designing each tool to perform only one task. It is better to separate
search_file()andupdate_file()than to bundle them into a singlesearch_and_update_file(). Tools with compound functionality make it easy for agents to produce unintended side effects.
The Most Common Mistakes in Practice
- Giving the agent too many tools — Handing an agent every available tool causes it to wander. Enforce the principle of least privilege.
- Keeping context outside the codebase — Knowledge that lives only in Slack or Confluence simply doesn't exist for the agent.
- Designing the harness only once — As the codebase evolves, so must the harness. Regular reviews are essential.
Closing Thoughts
Harness engineering in one sentence: "The success or failure of an AI agent depends not on the model, but on the environment surrounding the model." The era of refining prompts is over. Designing an environment in which agents can make sound judgments is now the core competency.
Three steps you can take right now:
- Context audit — Run
git grep -r "TODO\|FIXME\|slack.com\|notion.so"in your terminal to find knowledge links that have escaped the codebase. Also open your team onboarding docs and move every item marked "ask someone directly" into/docs. - Write the IMPACT checklist — Apply the 6 IMPACT elements to the agents you're currently using and find the gaps. If Authority is blank, start by defining the list of files the agent must never touch.
- Start small — Begin with the 2-agent pattern (research + writing, or planning + execution), get comfortable with the pattern, then expand to 3 agents.
In a world where models have become commoditized, the team that designs the better harness wins.
Next article: Multi-agent orchestration patterns — when you have more than 3 agents, how do you coordinate them? A comparison of the state-machine approaches used by LangGraph and CrewAI.
References
- Harness engineering: leveraging Codex in an agent-first world | OpenAI
- Effective harnesses for long-running agents | Anthropic Engineering
- Harness engineering for coding agent users | martinfowler.com (Birgitta Böckeler)
- OpenAI Introduces Harness Engineering: Codex Agents Power Large-Scale Software Development | InfoQ
- Anthropic Designs Three-Agent Harness for Long-Running AI Development | InfoQ
- The Anatomy of an Agent Harness | Daily Dose of Data Science
- Agent Engineering: Harness Patterns, IMPACT Framework & Coding Agent Architecture
- What is Harness Engineering? Why It's Emerging as the Core of AI Agent Development in 2026 | Channel.io
- Unlocking the Codex harness: how we built the App Server | OpenAI


